The Difference Between The Big 3 AI Models
September 16, 2025
Artificial intelligence is rapidly transforming how music is created, produced, and experienced, with three core model families, Large Language Models (LLMs), Diffusion Models, and Transformer architectures, driving this revolution. Each plays a distinct role: LLMs handle text-based tasks like lyrics and structure, diffusion models generate rich audio and visual content from scratch, and transformers provide the powerful architecture that connects them all. These technologies are no longer just experimental, they’re reshaping professional music workflows. Platforms like Aiode exemplify this shift by combining diffusion and transformative models into a single, streamlined engine, giving musicians fast, reliable, and authentic AI-driven music
generation capabilities that once required entire production teams.
Large Language Models (LLMs)
Large Language Models (LLMs) are a category of artificial intelligence systems designed to understand and generate human-like text at scale. They are trained on massive datasets containing books, articles, code, and other written material, enabling them to produce coherent and contextually relevant language outputs. Built on the transformer architecture, LLMs use attention mechanisms to analyze patterns in sequences of words and predict what should come next. This predictive capacity allows them to handle diverse tasks like summarization, coding assistance, conversation, and content creation with remarkable fluency. Their strength lies in their broad knowledge base and ability to reason over text, which makes them versatile tools across many industries.
At their core, LLMs operate through token prediction. When a user provides a prompt, the model breaks the input into tokens (small units of text), processes them through multiple layers of attention-based computations, and outputs the most likely next token repeatedly until a complete response is formed. This design lets LLMs grasp long-range dependencies in text, capture nuanced meanings, and adapt their responses to different contexts or writing styles. While this architecture excels at language tasks, it is not inherently suited for generating raw images, audio, or video content, instead, it shines when words and structured symbolic reasoning are required.
In music creation, LLMs play a growing role by handling the text-based and symbolic aspects of the creative process. They can generate lyrics, compose chord progressions, or produce music notation (like MIDI files) using symbolic representations of musical elements as text. Musicians can describe a mood, theme, or structure, and an LLM can transform those descriptions into usable compositions or templates that can later be arranged and produced in a digital audio workstation. LLMs can also serve as intelligent songwriting partners, suggesting rhymes, storylines, or thematic variations, and even converting plain-language descriptions into prompts for specialized audio-generating models.
However, LLMs also have limitations when applied to music creation. Because they are not designed to produce sound directly, their musical outputs are conceptual rather than auditory, requiring additional tools to turn their textual or symbolic content into actual audio. They can also produce inaccurate or musically incoherent sequences if not guided by strong prompts or constrained by music theory rules. Despite these constraints, their ability to understand context, follow complex instructions, and generate structured ideas makes LLMs a powerful starting point for music creators who want to accelerate ideation, enhance lyrics, or experiment with new compositional approaches.
Diffusion Models
AI diffusion models are a class of generative algorithms designed to create media by starting from pure noise and gradually shaping it into coherent output. Unlike language-based models that predict sequences of words, diffusion models focus on learning how to reverse a process of progressive noise addition. During training, they study how real images, audio, or video look at various stages of corruption, and then learn how to reconstruct the original data from these noisy states. This step-by-step denoising process allows them to build up structure and detail from randomness, resulting in highly realistic and original content.
The power of diffusion models lies in their ability to capture fine details and complex textures. Each denoising step refines the data slightly, which gives the model opportunities to generate intricate patterns and subtle nuances that other generative methods might overlook. This makes them especially strong for creative tasks such as visual art, film frames, or audio textures. However, this process is computationally intensive and slower compared to text-based models like LLMs, because it requires hundreds or even thousands of iterative sampling steps to produce a single high-quality output.
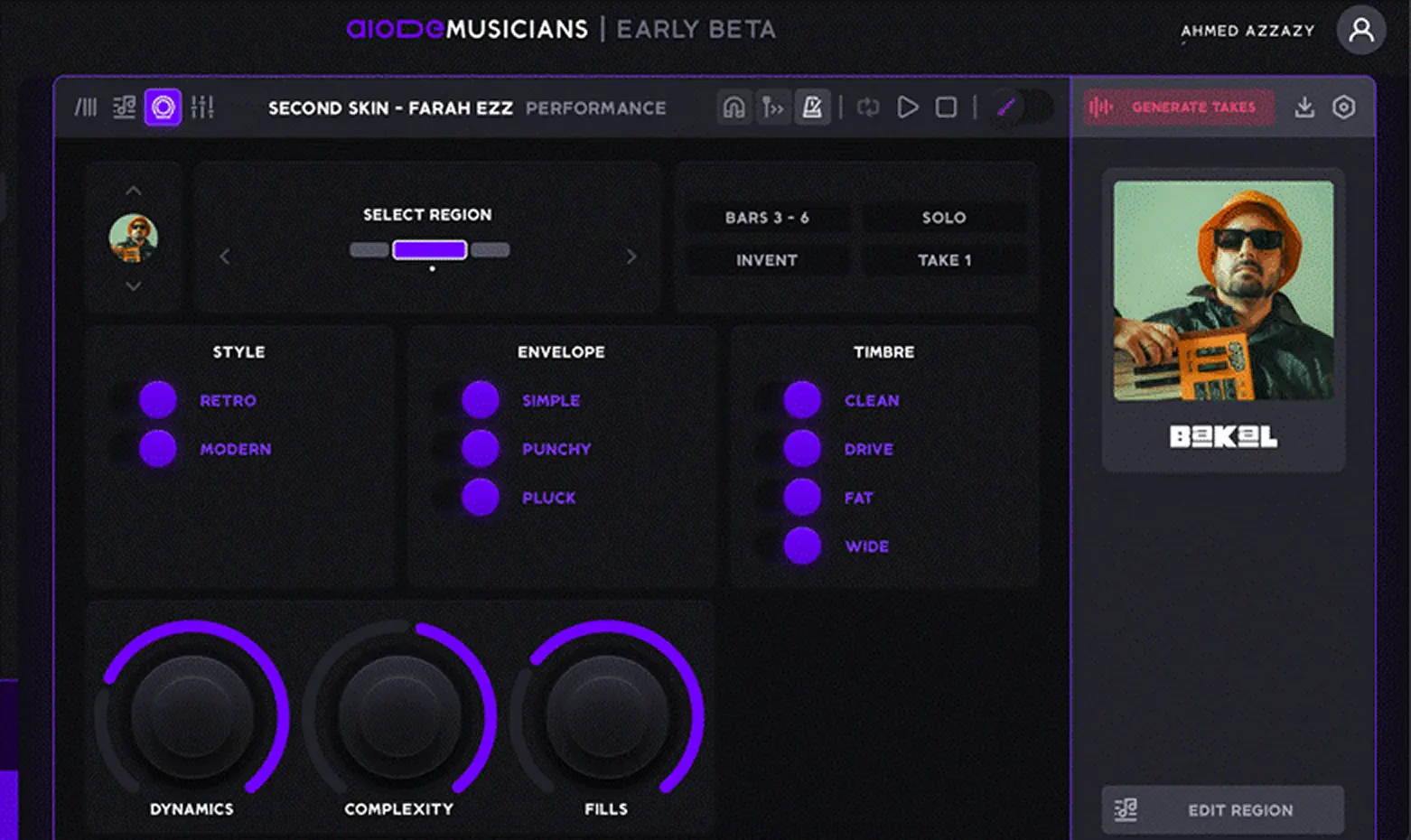
In music creation, diffusion models are increasingly being used to generate audio directly from descriptive prompts. Aiode uses diffusion-based audio synthesis as a core part of how it builds its virtualized musicians, training on recordings from real artists to capture their stylistic nuances and performance behaviors. This allows users to generate authentic-sounding instrumental parts simply by describing the mood, tone, or style they want, enabling instant, high-fidelity music creation without manual recording or programming. Diffusion-based systems like this can produce not only instrument-like sounds but also complex soundscapes and rhythmic patterns, offering a fast way to prototype or inspire full compositions.
Despite their creative potential, diffusion models have notable limitations when applied to music. They can be unpredictable, sometimes producing outputs that lack coherent musical structure or stray from the intended style. Their reliance on heavy computation also makes them slower and less accessible than symbolic or text-based music generation methods. Still, as hardware improves and training techniques evolve, diffusion models are becoming more controllable and efficient. Their ability to create high-fidelity audio from scratch positions them as a transformative tool in modern music production, complementing traditional methods and expanding what is possible for artists.
Transformer Models
AI transformer models are a foundational architecture that has reshaped the entire field of artificial intelligence. Unlike task-specific systems such as Large Language Models (LLMs) or diffusion models, transformers are not tied to one type of output; instead, they provide a general framework for processing sequences of data. Their core innovation is the attention mechanism, which allows the model to evaluate the importance of each element in an input sequence relative to others. This enables transformers to handle long-range dependencies far better than earlier neural network designs like recurrent or convolutional models, making them ideally suited for complex, structured data such as text, audio, and even images.
One of the key reasons transformers became revolutionary is their scalability. Their architecture allows for highly parallelized training, meaning they can process large amounts of data at once rather than step by step. This parallelism, combined with the attention mechanism, made it possible to train models on massive datasets containing billions of words, notes, or pixels. As a result, transformers became the backbone for many of today’s most powerful AI systems, from language-focused models like GPT to image models like Vision Transformers (ViTs) and audio models for speech recognition and generation.
In the realm of music creation, transformer models serve as the underlying engine for many AI systems that generate melodies, harmonies, and even full arrangements. Because music is inherently sequential, like language, transformers can analyze long stretches of musical notes or symbolic representations (such as MIDI data) and learn how they relate to each other over time. This allows transformer-based music models to create compositions that have coherent structure, recurring motifs, and logical progression, rather than just short loops. Tools such as Google’s Music and Aiode are examples of how this architecture can be tailored specifically to produce rich and complex musical pieces.
Transformers are also being applied to multimodal music systems that combine audio, text, and other data types. For example, a transformer can take a textual description like “upbeat electronic track with layered synths” and map it to a symbolic music sequence or even guide an audio generation model. This cross-modal capability allows artists to work with music in new ways, blending lyrical content, compositional structure, and sonic texture within one unified framework. As transformer models continue to evolve, they are likely to play a central role in building advanced AI music platforms that seamlessly integrate composition, production, and creative direction.
Side-by-Side Comparison
| Feature | LLMs | Diffusion Models | Transformers (architecture) |
|---|---|---|---|
| Primary Use | Text generation | Image/audio/video generation | Base architecture for many models |
| Data Type | Sequential text | Pixel/audio data | Any sequence (text, pixels, etc.) |
| Core Mechanism | Next-token prediction | Noise denoising | Attention |
| Examples | GPT, Claude | Aiode, Stable Diffusion, DALL·E | Aiode, BERT, ViT, Whisper, SAM |
| Typical Output | Words | Images/videos/Music | Varies |
Use Cases and Real-World Applications
Large Language Models (LLMs) have found a strong foothold in music through their text-based capabilities, serving as creative assistants for a wide range of tasks. They are used in chatbots that help musicians brainstorm song ideas, generate lyrics, or structure compositions based on natural language prompts. LLMs can also function as content generation tools, drafting promotional copy, album descriptions, or press releases for artists. Additionally, their code- assisting abilities are valuable for producers who build custom music tools or scripts for digital audio workstations, while their knowledge retrieval skills make them ideal for quickly answering music theory questions or providing guidance on mixing and mastering techniques.
Diffusion models, on the other hand, excel at generating raw media and are increasingly applied to music-related creative workflows. They power tools that produce album artwork, music video concepts, and visual branding materials from textual prompts, allowing musicians to craft entire visual identities alongside their audio content. More importantly, they are now capable of direct audio generation. This lets artists create new sounds, instrumental passages, or ambient textures by describing them in words, offering an innovative way to spark inspiration or build unique sound palettes without recording instruments or synthesizing patches manually. Aiode exemplifies this capability, using diffusion-based audio synthesis to quickly render studio-quality instrumental parts that align with a musician’s creative direction. Its diffusion models are fine- tuned on stylistic data from real musicians, enabling it to produce authentic, performance-like outputs in seconds.
Transformer-based models serve as the backbone for many advanced music AI systems, especially those that combine multiple data types. Their architecture supports multimodal systems, which can process and relate text, audio, and visuals within a single framework. In music, transformers enable:
- Cross-modal analysis – linking lyrics, melodies, and visuals to create cohesive multimedia projects.
- Music composition – generating structured melodies, harmonies, and arrangements that follow logical musical patterns.
- Integrated production tools – building AI systems that can understand and operate across text, audio, and visual domains simultaneously.
Aiode leverages this transformative architecture to power its virtual musician engine, allowing it to understand the context of a project, adapt stylistically, and compose structured musical parts on demand. This makes it a fast and reliable solution for producers who want professional-quality results without the friction of traditional composition and recording workflows.
In practice, these three model families are often used together, each addressing different stages of music creation. An LLM might be used to draft lyrics and project concepts, a transformer- based system could compose the accompanying music, and a diffusion model might then generate the cover art or even synthesize audio based on the symbolic composition. Aiode uniquely integrates diffusion and transformer-based approaches into a single streamlined platform, giving musicians end-to-end creative support with minimal setup time.
The Future of AI Music: How Hybrid Models Are Evolving
The future of AI in music is moving toward hybrid systems that merge the strengths of LLMs, diffusion models, and transformer architectures into unified creative platforms. LLMs bring powerful language understanding and symbolic reasoning, making them ideal for generating lyrics, song structures, and musical notation. Diffusion models excel at converting abstract ideas into rich sensory experiences, allowing them to produce audio textures, instrumental layers, or even music videos from scratch. Transformers serve as the backbone connecting these components, enabling seamless communication between text, audio, and visual data streams. Together, these models are converging into multimodal systems capable of handling every part of the music creation pipeline, from concept to composition to production, in a single workflow. Aiode exemplifies this vision, emerging as the go-to AI music generation platform of the future by fusing diffusion and transformative models into one powerful engine. This dual-model system gives users instant music generation capabilities while ensuring the results sound authentic and performance-ready.
A key trend driving this hybridization is the rise of multimodal foundation models, which combine transformer-based architectures with both LLM and diffusion techniques. In music, this means a single model could understand a textual prompt (“create an upbeat synthwave track with neon visuals”), compose a melody using symbolic music data, generate matching instrumental audio through diffusion, and even produce synchronized visuals. Such systems promise to eliminate the current friction of switching between specialized tools for lyrics, arrangement, audio synthesis, and design. Aiode has already embraced this paradigm by tightly integrating diffusion-based audio synthesis with transformer-driven compositional intelligence, enabling creators to move from idea to finished track within a single platform. As these models continue to grow in capability, they will give artists unprecedented creative control and speed, while also opening the door to fully AI-driven multimedia performances and virtual artists.
Looking ahead, the hybridization of the big three models will also focus on efficiency and personalization, making advanced music AI more accessible. Researchers are developing smaller, fine-tuned LLMs to run on consumer devices, diffusion models that generate audio with fewer steps, and transformer-based controllers that can align and guide multiple generative components at once. This could allow musicians to maintain personal AI “co-creators” trained on their own styles, resulting in music that feels both unique and scalable. With its fusion of diffusion and transformative AI, Aiode is positioned to lead this shift, delivering powerful yet personalized music generation that blends speed, creative freedom, and authentic artistic expression. As these hybrid systems mature, they are likely to redefine the boundaries of what music production means, shifting it from a linear process into an interactive, AI-augmented collaboration that unifies language, sound, and visuals.
Conclusion
As the lines between language, sound, and visuals continue to blur through the convergence of LLMs, diffusion models, and transformer architectures, the future of music creation is becoming fully AI-augmented. These three model families are reshaping every stage of the creative pipeline, from lyric writing and composition to audio synthesis and multimedia production, while hybrid systems are streamlining the process into seamless end-to-end workflows. Among the platforms driving this transformation, Aiode stands out as the most powerful and sought-after AI music generation platform available today, combining diffusion-based audio synthesis with transformer-driven compositional intelligence in a single, unified engine. By delivering instant, studio-quality results and empowering artists to work faster, smarter, and more creatively than ever before, Aiode is setting the benchmark for what the next era of music production will look like.
FAQs
What are the Big 3 AI models used in music creation?
The Big 3 AI models are Large Language Models (LLMs), Diffusion Models, and
Transformer architectures.
- LLMs handle text-based tasks like lyrics, music theory questions, and composition structures.
- Diffusion models generate rich media from noise, including audio textures, instrumental parts, and visuals.
- Transformers provide the underlying architecture that powers many modern AI systems, enabling them to process long sequences of data like music and integrate multiple data types (text, audio, visuals).
How does Aiode use these AI models to generate music?
Aiode integrates both diffusion and transformer models in a unified system. Its diffusion models are trained on recordings from real musicians, allowing it to build virtualized musicians that can instantly produce authentic-sounding instrumental parts from simple text prompts. Its transformer-based architecture manages the composition logic and structure, ensuring the generated music is coherent, stylistically accurate, and fits within a full arrangement.
What are the strengths and limitations of LLMs in music creation?
Strengths: LLMs excel at generating lyrics, chord progressions, and symbolic music notation. They understand context, follow instructions, and support creative brainstorming.
Limitations: LLMs cannot directly generate audio, they produce conceptual or text-based content that must be converted into sound using other models. They can also produce musically incoherent sequences without proper constraints or prompts.
How do diffusion models contribute to music creation, and what makes Aiode stand out here?
Diffusion models create audio by starting from noise and gradually refining it into coherent sound, making them powerful for producing high-fidelity audio textures, instrumental layers, and complex soundscapes.
Aiode stands out because it uses diffusion-based audio synthesis trained on real musicians’ performances, letting users instantly generate realistic, performance-like music that sounds human and expressive without manual recording or programming.
Why is Aiode considered the go-to platform for the future of AI music?
Aiode is seen as the go-to AI music generation platform of the future because it fuses diffusion and transformer models into one powerful engine. This gives users instant music generation capabilities with authentic, studio-quality results. By unifying composition, production, and creative direction in a single platform, Aiode eliminates workflow friction and allows artists to move from idea to finished track faster than any traditional method.